The RAG Plateau
Retrieval-Augmented Generation was a breakthrough. By decoupling a language model's knowledge from its parameters — grounding responses in retrieved documents rather than memorized training data — RAG solved two critical problems simultaneously: hallucination and knowledge currency. The model could be wrong, but the retrieved documents could be right, and the combination was far more reliable than either alone.
But RAG has plateaued. The architecture that was revolutionary in 2023 is now a ceiling. And the limitations are becoming impossible to ignore.
The core issue is conceptual: RAG treats knowledge as a search problem. You have a question. You search a corpus. You retrieve relevant chunks. You feed them to a model. The model synthesizes an answer. This is fundamentally a retrieval pipeline with a language model at the end — a sophisticated version of the same search-and-summarize pattern that has defined information access for decades.
RAG asks: "What documents answer this question?" Contextual intelligence asks: "What does this question mean in the context of everything we know?"
The Five Limitations of Classical RAG
To understand why we must move beyond RAG, we need to be precise about where it fails:
1. Chunk Boundary Blindness
RAG systems split documents into chunks for embedding and retrieval. This creates an artificial boundary problem: insights that span multiple chunks — or that require synthesizing information across distant parts of a document — are systematically underrepresented. The system retrieves chunks, not understanding.
2. Static Embedding Spaces
Most RAG systems embed documents once and retrieve against a fixed vector space. But meaning is not static. The relevance of a passage changes based on who is asking, why they are asking, and what they already know. A fixed embedding cannot capture this dynamism.
3. Retrieval-Reasoning Disconnect
In classical RAG, retrieval and reasoning are sequential stages: retrieve first, reason second. This means the reasoning model cannot guide the retrieval process. It cannot say, "I need more context about X before I can answer this." It gets what the retriever provides and must work with it.
4. Absence of Epistemic State
RAG has no concept of what it knows versus what it does not know. It retrieves whatever is most similar to the query and presents it with uniform confidence. There is no mechanism for expressing uncertainty, identifying knowledge gaps, or distinguishing between well-supported claims and tentative inferences.
5. No Learning Loop
A RAG system that answers a thousand questions about the same topic learns nothing from the experience. Each query is independent. The system cannot identify patterns in what users ask, what they find helpful, or where the knowledge base has gaps.

Contextual Intelligence: The Next Paradigm
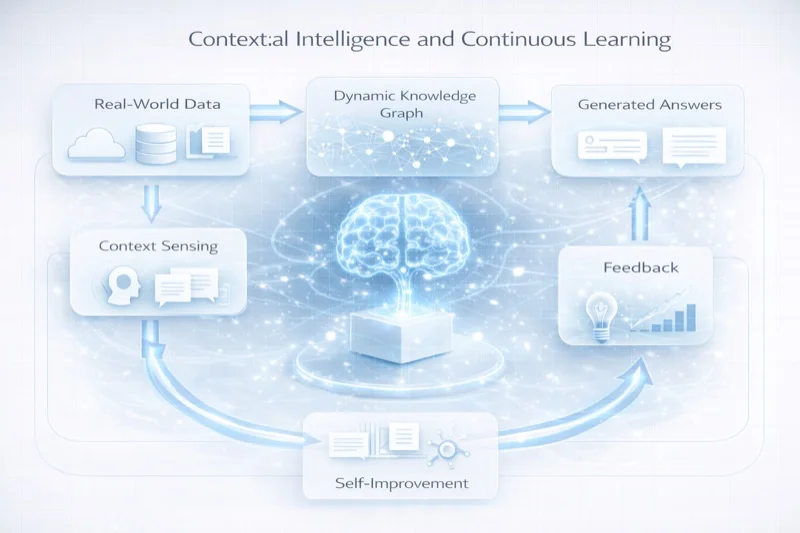
Contextual Intelligence is not an incremental improvement on RAG. It is a different architecture built on a different premise: that knowledge is not a collection of retrievable chunks but a dynamic, evolving graph of relationships that must be reasoned about, not merely searched.
Dynamic Context Synthesis
Instead of retrieving fixed chunks, a Contextual Intelligence system synthesizes context in real time. It begins with the user's query, models their likely intent and background knowledge, and then constructs a custom context window by traversing the knowledge graph — pulling in propositions, evidence, counter-arguments, and examples as needed.
This is not retrieval. This is reasoning about what context the model needs to provide a good answer. The system might decide that a senior researcher needs different context than a graduate student, even for the same question — and it assembles both windows dynamically.
Iterative Reasoning with Retrieval
In Contextual Intelligence, reasoning and retrieval are interleaved rather than sequential. The system reasons about what it knows, identifies what additional context it needs, retrieves it, reasons further, and iterates. This mirrors how human experts actually process complex questions — they do not retrieve all relevant information first and then think. They think, realize what they need, look it up, think more, and repeat.
// Pseudocode: Iterative reasoning loop
while (!sufficient_confidence(answer)) {
gaps = identify_knowledge_gaps(current_context, query);
if (gaps.length === 0) break;
new_context = knowledge_graph.traverse(gaps, {
reader_model: reader.expertise_profile,
depth: adaptive_depth(confidence_level),
include_contradictions: true
});
current_context = synthesize(current_context, new_context);
answer = reason(current_context, query);
}Epistemic Awareness
A Contextual Intelligence system maintains an explicit model of its own epistemic state. For every claim it makes, it can articulate its confidence level, identify the evidence supporting it, and flag areas of uncertainty. This is not a post-hoc calibration — it is built into the reasoning process itself.
For academic applications, this is transformative. A system that can say "I am highly confident about X based on three peer-reviewed sources, moderately confident about Y based on one preprint, and uncertain about Z because the available evidence is contradictory" is fundamentally more useful than one that presents all outputs with equal authority.
Continuous Learning
Every interaction with a Contextual Intelligence system enriches its knowledge graph. Not by modifying model weights — fine-tuning is expensive and brittle — but by updating the graph itself. New propositions are added. Existing propositions are reinforced or weakened based on usage patterns. Knowledge gaps are identified and flagged for human review.
This creates a virtuous cycle: the more the system is used, the better its knowledge graph becomes, the better its reasoning becomes, and the more useful it becomes to its users. Unlike RAG, which remains static between manual index updates, Contextual Intelligence evolves continuously.
Implementation: From Theory to Practice
The theoretical advantages of Contextual Intelligence are clear. The implementation challenges are equally real.
Knowledge graph construction remains the hardest problem. Decomposing existing documents into atomic propositions with rich metadata requires significant effort — either human curation or sophisticated NLP pipelines (or, increasingly, both). The quality of the graph determines the quality of the system.
Latency management is critical. Iterative reasoning with retrieval is inherently slower than single-pass RAG. Practical systems must implement intelligent caching, predictive context pre-loading, and graceful degradation strategies that provide fast initial responses while refining in the background.
Evaluation methodology is an open problem. Standard RAG benchmarks (context relevance, answer faithfulness, etc.) are necessary but insufficient for evaluating Contextual Intelligence. We need new metrics that capture adaptation quality, epistemic calibration, and long-term learning effectiveness.
The Road Forward
We are at an inflection point. The first generation of AI-augmented content systems — chatbots, RAG pipelines, copilots — proved that language models can be useful. The next generation must prove that they can be intelligent in a deeper sense: capable of sustained reasoning, genuine adaptation, honest uncertainty, and continuous improvement.
Contextual Intelligence is not the final answer. It is the next question, properly formulated. The research community, the engineering community, and the broader ecosystem of builders must now collaborate to explore its implications, test its limits, and refine its architecture.
The static web gave us access to information. RAG gave us access to answers. Contextual Intelligence will give us access to understanding. That is worth building toward.

Discussion