Why "AI-Enhanced" Is Not Enough
Most organizations approaching AI integration make the same mistake: they bolt intelligence onto existing architectures. A chatbot here. A recommendation engine there. A summarization feature stitched into a CMS that was designed in 2005. The result is a Frankenstein's architecture — technically functional but fundamentally incoherent.
AI-native architecture is a different proposition entirely. Rather than adding intelligence to a document-era system, it builds intelligence into the foundation. Every layer of the stack is designed with reasoning, adaptation, and evolution as first-class concerns.
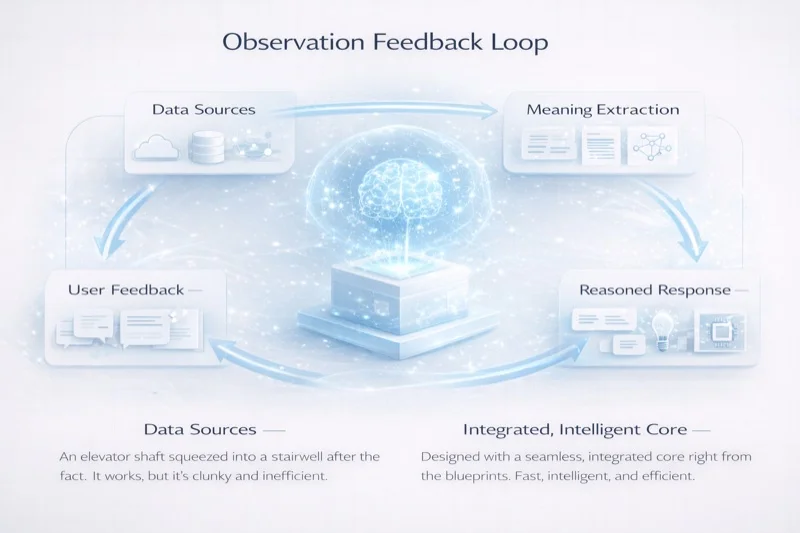
This is the difference between a building with an elevator shaft retrofitted into its stairwell and a building designed from the blueprints to move people vertically. Both have elevators. Only one works well.
The Webspinner Reference Architecture
The Webspinner Network has been developing a reference architecture for AI-native content systems. It comprises five distinct layers, each with clear responsibilities and well-defined interfaces.

Layer 1: The Semantic Substrate
At the base of the stack lies the Semantic Substrate — a structured representation of content that goes far beyond HTML or Markdown. Content in this layer is decomposed into atomic propositions, each tagged with metadata: source, confidence level, domain, relationships to other propositions, and temporal validity.
This is not a database. It is a knowledge graph where every node carries enough context for an intelligence layer to reason about it independently. The substrate is format-agnostic — it can render into HTML, spoken word, interactive visualization, or conversational exchange.
{
"proposition": "RAG architectures decouple knowledge from model weights",
"confidence": 0.95,
"domain": ["ai-architecture", "information-retrieval"],
"sources": ["arxiv:2312.10997", "internal:research-note-42"],
"valid_from": "2023-12",
"relationships": [
{"type": "supports", "target": "prop:cognitive-content-thesis"},
{"type": "contrasts", "target": "prop:fine-tuning-approach"}
]
}Layer 2: The Reasoning Engine
The Reasoning Engine operates on the Semantic Substrate to make real-time decisions about content delivery. It is not a simple lookup system. It maintains three concurrent models:
- Reader Model — An evolving representation of the current reader: their expertise level, reading history, engagement patterns, and inferred intent.
- Content Model — A dynamic map of the available knowledge, including gaps, contradictions, and areas of uncertainty.
- Context Model — The current interaction state: what has been presented, what questions have been asked, what the reader appears to need next.
The engine synthesizes these three models to produce a reasoning plan — a sequence of content decisions that optimizes for reader understanding rather than simple information delivery.
Layer 3: The Composition Layer
Once the Reasoning Engine determines what to present, the Composition Layer assembles it into coherent output. This is where atomic propositions become paragraphs, where data points become visualizations, where technical details become code examples or interactive demonstrations.
The Composition Layer is critical because it is where the system's intelligence becomes legible. A reader should never feel that they are interacting with a database — they should feel that they are reading a thoughtful, well-structured piece of writing that happens to be exactly what they needed.
Layer 4: The Presentation Surface
The Presentation Surface is the user-facing layer — the actual interface the reader sees and interacts with. In an AI-native architecture, this layer is unusually thin. It does not contain business logic or content decisions. Its sole responsibility is rendering composed content into the appropriate medium (web, mobile, voice, API) with appropriate styling and interaction affordances.
This separation is deliberate. By keeping the presentation layer thin, we ensure that the same intelligence can serve multiple surfaces without duplication. A research paper and a conversational interface can share the same Reasoning Engine and Composition Layer while presenting through entirely different surfaces.
Layer 5: The Observation Layer
Every interaction with the system generates data. The Observation Layer captures this data — not for surveillance, but for evolution. It tracks what works: which explanations lead to comprehension, which structures lead to engagement, which content paths lead to deeper exploration.
This layer feeds back into the Semantic Substrate, closing the loop. Over time, the system does not merely serve content — it improves it. Propositions that consistently confuse readers get flagged for revision. Knowledge gaps that readers repeatedly expose get queued for research. The content evolves.
Design Principles
The Webspinner architecture is governed by six principles that distinguish AI-native design from AI-enhanced retrofit:
- Intelligence is structural, not decorative. AI is not a feature bolted onto a content management system. It is the organizing principle of the entire stack.
- Content is composable, not monolithic. Every piece of content exists as atomic, recombinable units — not fixed pages or documents.
- Presentation is a projection, not the truth. What the reader sees is one of many possible renderings of the underlying knowledge graph.
- State is continuous, not sessional. The system maintains persistent models of readers, content, and interactions across time.
- Evolution is automatic, not manual. The system identifies its own weaknesses and improves without requiring human editorial intervention for every change.
- Sovereignty is non-negotiable. Reader data stays under the reader's control. Intelligence serves users — it does not extract from them.
Implementation Considerations
Building an AI-native architecture is not a weekend project. It requires rethinking data models, deployment infrastructure, observability pipelines, and team structures. Organizations accustomed to document-era CMS workflows will find the transition demanding.
Our recommendation is to start at the edges. Identify a single content domain — technical documentation, research output, training materials — and build a cognitive layer around it. Instrument heavily. Observe how readers interact with adaptive content versus static content. Let the data guide the expansion.
The tooling is maturing rapidly. The Webspinner ecosystem provides reference implementations for each architectural layer, from the semantic substrate to the observation pipeline. But the real challenge is not technical — it is conceptual. Organizations must internalize a new mental model: content is not a thing you produce. It is a system you cultivate.

Discussion